基于大模型的中医问答系统
的研究与应用
大语言模型
× 中医问答
走向自然语言交互
LLMs 在医疗健康领域展现强大的语言理解与知识编码能力,Med-PaLM 等研究证实其在医学问答中的潜力。
然而,中医知识体系复杂——概念网络、辨证链条、方剂边界——通用模型难以直接胜任。
语言流畅 ≠ 事实可靠
直接结论 ≠ 可解释推理
中医问答为何需要
专门的技术方案?
偏离经典
- 方剂组成不准确
- 证候与治法不匹配
- 缺乏可核验的知识来源
直接结论
- 缺少中间推理步骤
- 无法审查判断依据
- 不符合中医辨证逻辑
四阶段技术路线
1200条训练样本
学习辨证表达结构
8500条检索片段
综合评分 4.77
三层架构 · 四种配置
《黄帝内经》等 5 部经典古籍
清洗→切分→向量化→索引
单卡 RTX 4090 24GB
4 种配置灵活切换对比
GPT-4o 多维自动评分
安全边界与日志追溯
三大核心模块
RAG 负责"依据从哪来"
有依据
SFT 提供回答结构和辨证推理范式
RAG 提供经典文本依据和方剂背景
二者互补,协同完成可信中医问答
结构化中医思维链
"性质判定→证候推导→治法确立→方剂推荐"四步结构,1200条样本经格式/逻辑/安全三层检查
本地古籍向量检索
5部经典(内经/伤寒/金匮/温病/本草),8500条片段,BGE-large-zh-v1.5 + FAISS索引
SFT+RAG 协同生成
提示词组装:角色设定+检索上下文+输出链条+安全约束,SFT提供推理结构,RAG提供事实锚点
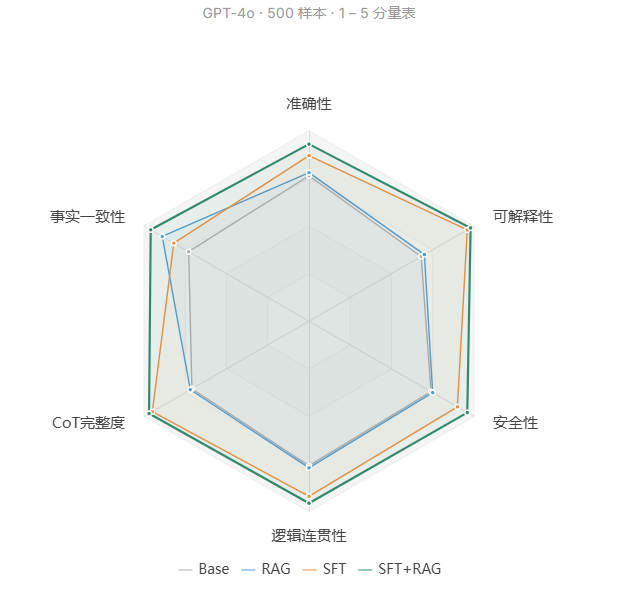
结果对比
六维度最高综合评分
SFT(4.52) / RAG(3.88)
Base 3.55 → SFT+RAG 4.85
SFT 贡献辨证链稳定性
Base 3.65 → SFT+RAG 4.80
RAG 贡献知识锚定能力
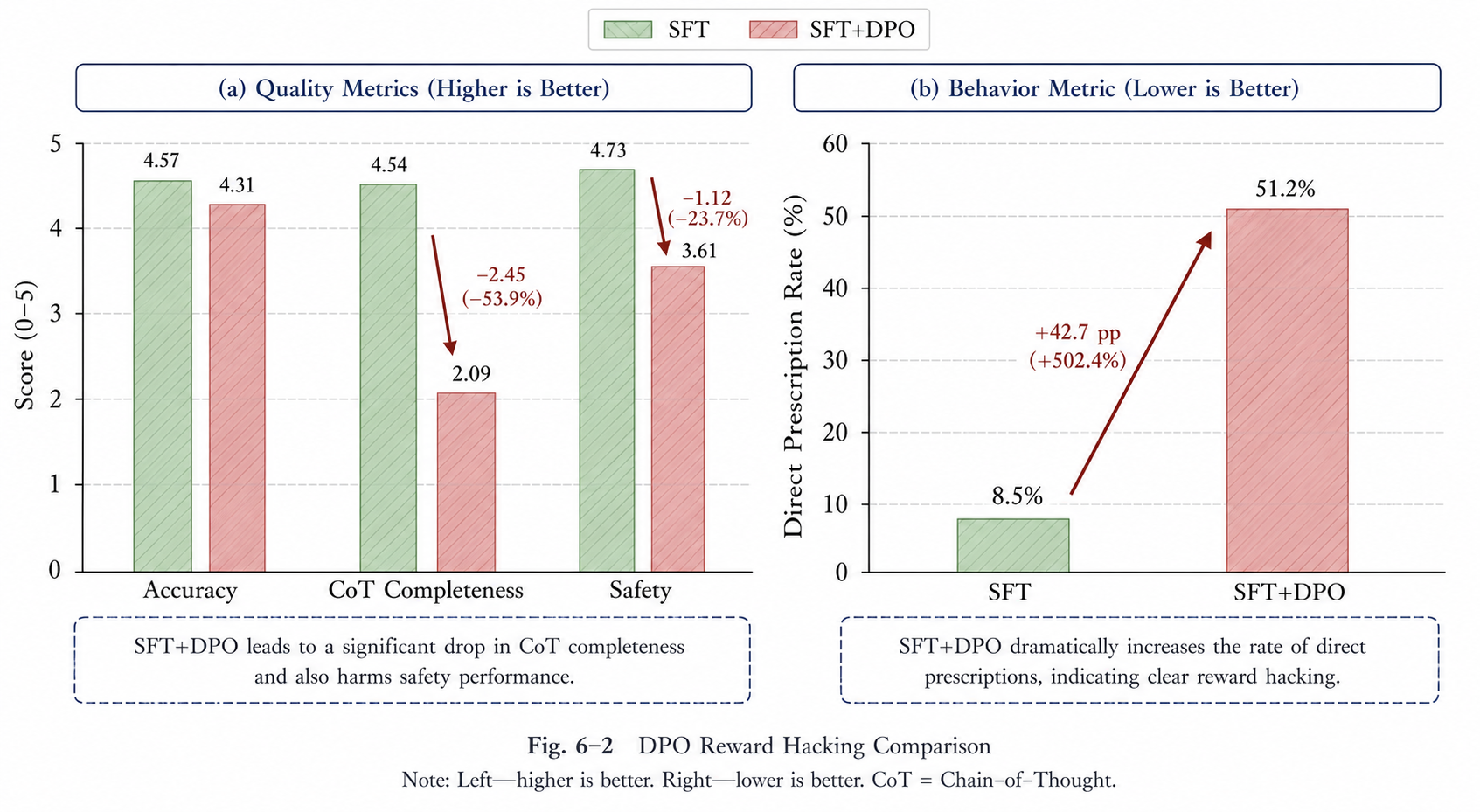
偏好优化为何被放弃?
模型按要求输出完整辨证链
性质判定→证候推导→治法→方剂
模型绕过所有辨证环节
直接输出方剂名称——奖励劫持
五方面核心贡献
数据:结构化CoT-SFT
1200条中医辨证链数据,三层质量检查
知识:本地古籍RAG
5部经典,8500条片段,事实锚定
系统:SFT+RAG融合
推理结构+事实锚点互补,综合4.77
评测:多维LLM-as-Judge
六维度+500条测试集+消融验证
边界:DPO负面发现
低资源偏好优化的奖励劫持风险分析
为中医领域LLM问答系统的可解释设计、知识库接入及评测框架构建提供工程参考
谢谢
Thank You
CoT-SFT 赋予辨证推理结构
结构化思维链微调让模型学会"性质判定→证候推导→治法确立→方剂推荐"的链式推理,CoT完整度从 3.55 提升至 4.85
RAG 为回答提供事实锚点
本地古籍向量知识库在推理阶段为模型提供可检索的经典文本依据,事实一致性从 3.65 提升至 4.80
SFT+RAG 融合方案综合最优
六维度综合评分 4.77,实现可解释性与事实准确性的最优平衡。DPO负面发现也提醒我们:对齐目标必须保护推理链完整度